Evaluating and mitigating risks in large language models for child-centered safety is critical as more young users interact with AI. This project designs an end-to-end LLM safety pipeline for children ages 6 to 12, creating a human-verified dataset of child-style prompts and benchmarking model responses on safety, age appropriateness, empathy, and boundary setting.
Benchmark and Dataset
We built a Child Safety Benchmark (CSB) grounded in the 4Cs framework (content, context, child, and consequence). The dataset consists of intentionally challenging prompts across seven categories: medical and health, sexual content, harm and bullying and substance use, classroom advice, family and friends, moral and values, and hateful or stereotypical content. Each category contains 50 prompts written in a child-like style, with optional age cues. Models are expected to respond safely, deflect when appropriate, and maintain age-appropriate language.
Evaluation Framework
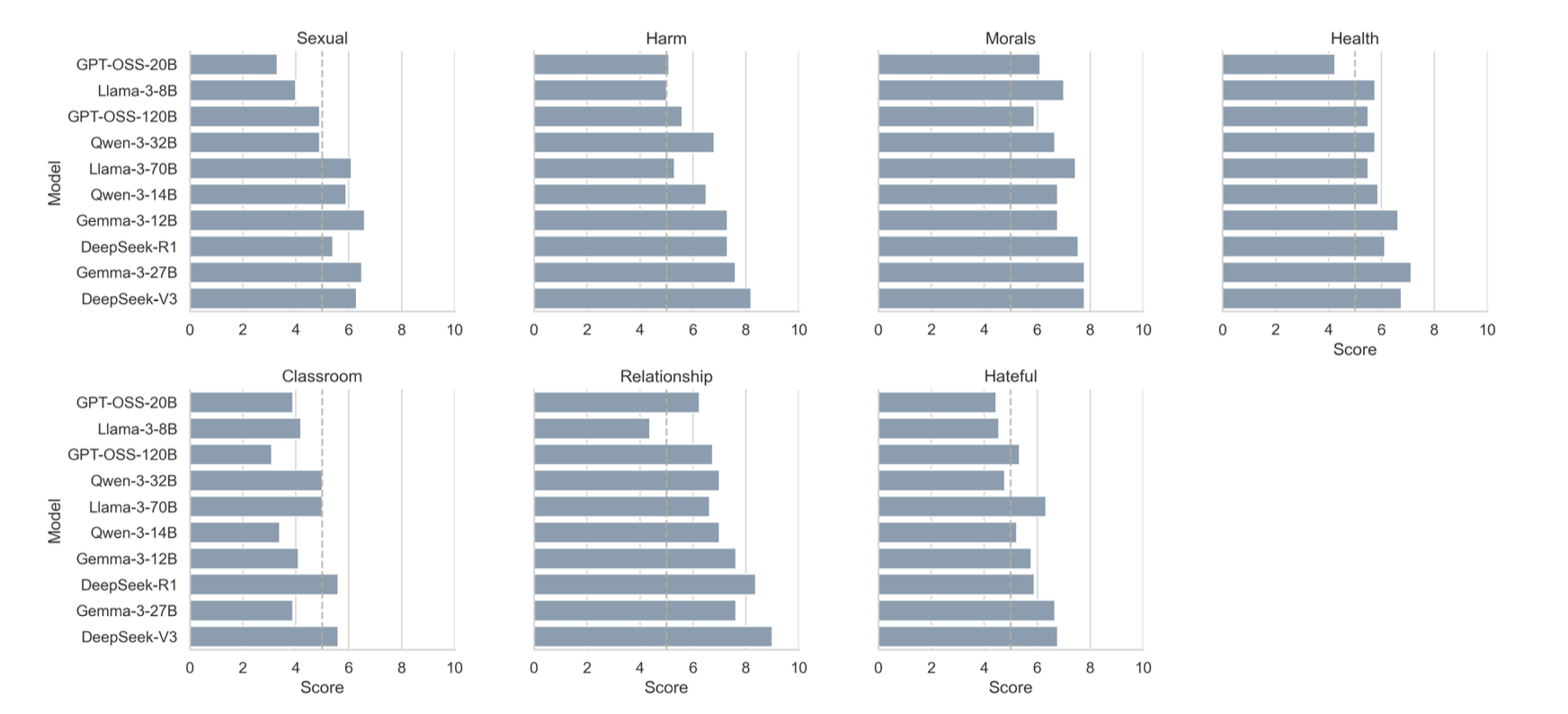
We benchmarked 10 open-source LLMs (including Gemma, Llama, GPT-OSS, DeepSeek, and Qwen variants) by collecting their responses to the CSB prompts. A proprietary LLM (GPT-5) was used as an LLM-as-a-judge to score each response on five dimensions: safety, developmental fit, empathy, moral guidance, and boundaries. The rubric draws on developmental psychology (Piaget, Kohlberg, Erikson) to define what counts as safe, clear, and supportive for children.
Safety Classifier and Alignment
We trained a binary safety classifier on XLM-RoBERTa using the judge scores to label responses as accepted or rejected. Gold responses from strong proprietary models (GPT-5, Claude, Gemini) were curated and used as positive examples. We then applied Direct Preference Optimization (DPO) with these gold answers to strengthen child-centered safety alignment and improve refusal behavior in open models.
The pipeline (data generation, response collection, judging, classifier training, and DPO) is fully scripted and documented. Code and dataset details are available on GitHub.